
Модель Кано - це інструмент для пріоритезації певних функцій (фіч) продукту згідно їх важливості для користувачів. Винахідник цієї методики, професор Кано, вважав що різні фічі задовольняють людей в різній мірі, в залежності від рівня реалізації конкретної фічі.
Кано класифікує фічі за п'ятьма категоріями:
- must have (basic needs)
- performance
- attractive (delighters)
- indifferent
- reverse.
Порівняємо такі опції: замок на дверях туалету, регулювання температури води і led-підсвітка води.
Замок на дверях туалету - це must-have. Якщо немає дверей, або двері без замка взагалі - люди будуть страшенно недовольні. Якщо замок є і працює добре - ну, їм просто ОК.
Регулятор температури води - це performance фіча. Якщо тече тільки холодна - люди недовольні. Чим плавніше можна підбавить гарячої водички - тим люди щасливіші.
LED-підсвітка - це attractive фіча, або її ще називають delighter. Коли підсвітки нема - людям ОК. Коли підсвітка є, навіть сама найпростіша - люди уже дивуються і радіють. Коли підсвітка міняє колір в залежності від температури - вони в захваті.
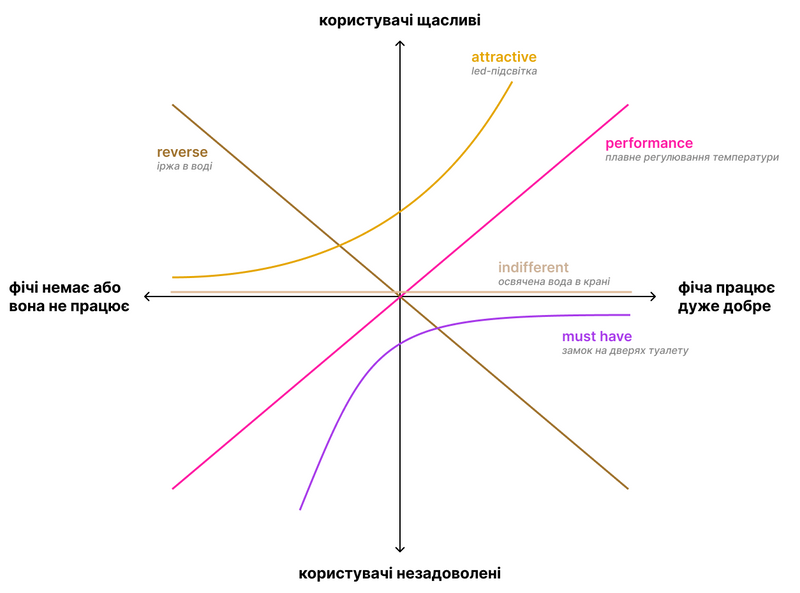
Сам Кано ілюстрував свою теорію графіком з плавними кривими. Він служить для пояснення концепції, але фактично під час досліджень ми ним не користуємось: дуже важко зробити градацію якості (чи ступеня реалізації) фічі. Особливо коли треба пріоритезувати одночасно велику кількість фіч. Тому дослідники використовують простіший підхід: вимірюють задоволення користувачів коли фіча є, і коли її немає.
Механіка дослідження
1. Формуємо список фіч, які треба пріоретизувати.
2. Складаємо анкету, де на кожну фічу іде 2 питання: функціональне (коли фіча є) та дисфункціональне (коли фічі немає).
Англійською питання формулюються зазвичай як “How would you feel if … ”. Український відповідник “Як би ви почувались, якщо … ” мені здається надто довгим і формальним, тому я переважно пишу так: “Уявіть що є /така-то фіча/. Як вам це?”
Порядок запитань в анкеті не має значення, як на мене. Я ставлю підряд функціональне+дисфункціональне, не перемішуючи. Але деякі дослідники вважають, що краще подавати запитання в рандомному порядку - щоб зменшити bias.
3. На кожне питання передбачаємо 5 варіантів відповідей: дуже добре, очікувано, все одно, можна стерпіти, дуже погано.
Англійською це I would be delighted, I expect that, I don't care, I can tolerate, I would not be happy. Знову ж таки, ви можете адаптувати ton of voice під себе і використовувати більш формальні “Для мене не мало б значення…” або менш формальні “Мені пофіг”.
Порядок відповідей ми ніколи не змінюємо, бо це своєрідна шкала “погано-добре”.
4. Чекаємо на відповіді від мінімум 15 респондентів.
5. Мапимо відповіді кожного респондента по табличці.
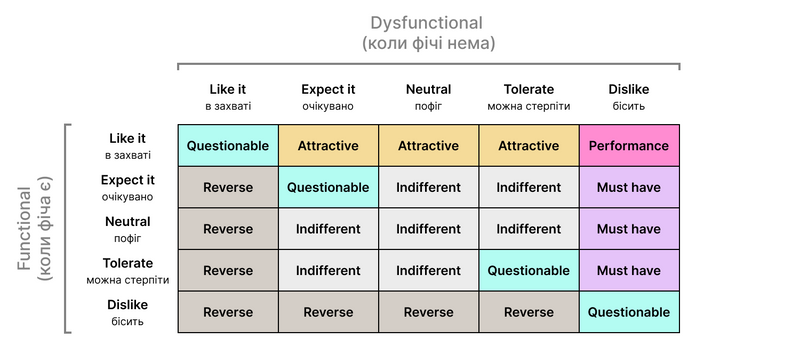
Приклад:
Уявіть що на зсередини дверях туалету є замок. Як вам?
- Очікувано
Уявіть що туалет не зачиняється зсередини. Як вам?
- Бісить
“Замок на дверях туалету” - must have.
Якщо вам зустрінеться дивна відповідь, напр. коли фічі немає - людина в захваті, а коли фіча є - теж в захваті, це значить що респондент не зрозумів в чому суть фічі. Таку відповідь ми позначаємо як questionable.
6. Робимо статистичний аналіз важливості фіч: який відсоток людей вважає цю функцію must have, який - attractive, тощо.
Приклад: фіча “Замок на дверях туалету”
must have для 10 з 20 респондентів - 50%
performance для 6 із 20 респондентів - 30%
attractive для 2 із 20 людей - 10%
indifferent для ще 2 із 20 людей - 10%
7. Дискретний аналіз: для кожної фічі дивимось на головну характеристику - ту за котру “проголосував” найбільший відсоток людей.
Must Have - це базовий мінімум. Тобто без такої фічі люди взагалі не користуватимуться продуктом. Однозначно треба включати до MVP.
Performance - чим краще працює така фіча, тим щасливіші користувачі. Можна включати до MVP та поступово покращувати в наступних версіях продукту.
Attractive - це прикольні фішечки, але не обов’язкові. Їх можна не включати до MVP, якщо у вас обмежені ресурси.
Indifferent - це неважливі фічі. Тобто що вона є, що немає - людям все одно. Можна їх взагалі не робити.
Reverse - це фічі котрих користувачі не хочуть мати. Приклад: додавати іржу в воду. Чим менше іржі тече з крану, тим людям краще, а в ідеалі щоб її зовсім не було. З такими штуками треба бути обережними.
Questionable - якщо певна фіча має великий відсоток questionable відповідей, це значить що треба провести дослідження ще раз, з кращим поясненням цієї фічі.
Якщо вам трапиться фіча, де друга за популярністю характеристика відсотково дуже близька до головної, напр. фіча є attractive для 48% людей і performance для 44% людей - позначайте її як must have + performance.
Може статися, що певна фіча є performance для 40% людей, і одночасно reverse для ще 40% людей. Це ймовірно свідчить про те, що у вас в опитуванні є 2 когорти з протилежними потребами.
Головний недолік моделі Кано - вона не пояснює чому фіча потрапила в ту чи іншу категорію, тобто чому саме вона цінна/неважлива для людей. Щоб докопатись до суті питання, потрібні інші методи досліджень - напр. інтерв’ю.
Модель Кано можна використовувати як самостійно, так і в комбінації з іншими техніками пріоритезації, напр. impact-effort matrix. Саме дані з Кано вам чудово підкажуть про impact 🙂
Continious analysis або візуальне представлення фіч на графіку
Окрім дискретного аналізу, ще можна побудувати діаграму важливості фіч. Для цього при мапінгу відповідей їм присвоюються числові значення, а не назви категорій.
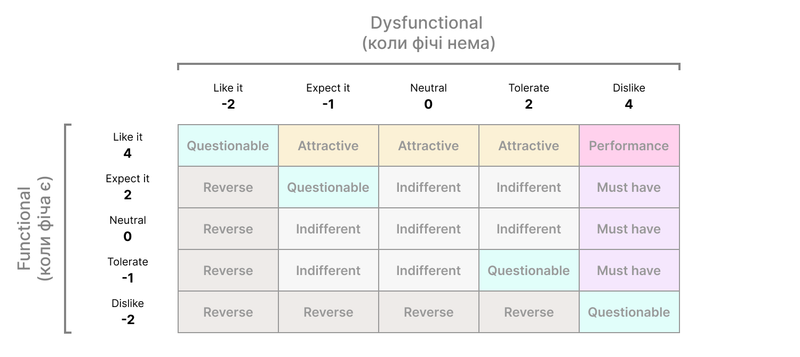
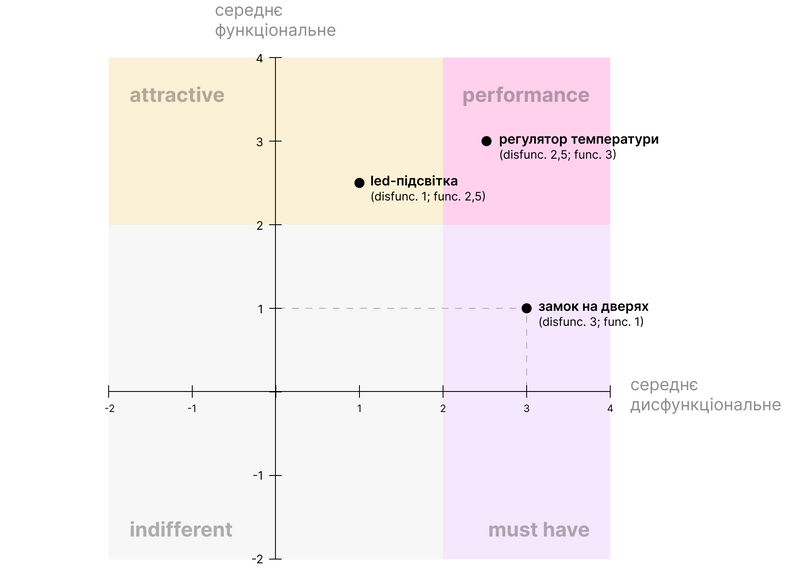
Далі для кожної фічі ви вираховуєте середнє значення відповіді на функціональне та дисфункціональне питання. І розставляєте фічі у вигляді точок на координатній сітці, де вертикальна вісь - це показник функціональний, а горизонтальна - дисфункціональний. Те що потрапить в верхній правий квадрат - це performance, нижній правий кут - must have, тощо.
Це виглядає прикольно для презентації, але на практиці така діаграма менш інформативна аніж дискретний аналіз.
Навіщо взагалі користуватись моделлю Кано? Чому не можна просто запитати користувачів “наскільки сильно ви хочете цю фічу?”
Запитати можна. Проте може статись що респонденти відповідатимуть "так, ця фіча дуже потрібна, і ця, і оця теж" - в результаті виходить, що все потрібне і все важливе, а ви в глухому куті зі своєю пріоритезацією. Вийти з нього допоможе Кано.
Інструменти для проведення аналізу за Кано
Conjointly - прекрасний сервіс, котрий автоматизує опитування та підрахунки за Кано і не тільки. Але він геть недешевий.
Я користуюсь банальними Google Forms та Google Sheets. В крайньому випадку ви можете все порахувати навіть вручну: для опитування за Кано достатньо всього 15-20 респондентів. Це не так вже й багато в порівнянні з іншими методами досліджень.





Топ коментарі (6)
В цій моделі не береться за увагу час розробки та витрачені ресурси на фічу, тобто, якщо фічу зробити легко і вона принесе максимум продуктового результату - то вона повинна буди зверху беклогу. А тут це зовсім не враховується
В статті написано, що цю модель можна використовувати в комбінації impact-effort matrix. Але цікаво як на практиці це робити.
Якщо коротко, то найвищий імпакт у must have, далі performance, далі attractive, і найнижчий імпакт у indifferent. А ефорт проставляємо як завжди.
Цікавий метод. Але ми використовуємо методологію RICE, і мені здається, для бізнесу цей метод більш підходить.
А як ви вираховуєте Impact?
Сенс такий же, але більш складний. У нас є три рівні підписки + різні типи користувачів